
2025年的AI芯片市场正处于微妙的转折点。英伟达凭借Blackwell在技术和市场份额上保持领先,但谷歌TPU的全面商业化开始动摇其定价权。据SemiAnalysis测算配资优秀配资门户,OpenAI仅凭“威胁购买TPU”就迫使英伟达生态链做出了实质性让步,使计算集群总拥有成本下降约30%。
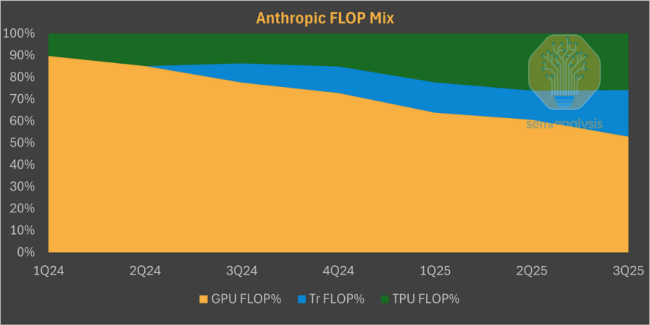
随着Anthropic采购高达1GW的TPU细节曝光,谷歌转型为直接向外部出售高性能芯片与系统的“商用芯片供应商”。当OpenAI可以用“威胁购买TPU”换取折扣,当Anthropic用TPU训练出超越GPT-4的模型,当谷歌愿意开放软件生态并提供金融杠杆时,英伟达高达75%的毛利率神话变得不再牢不可破。
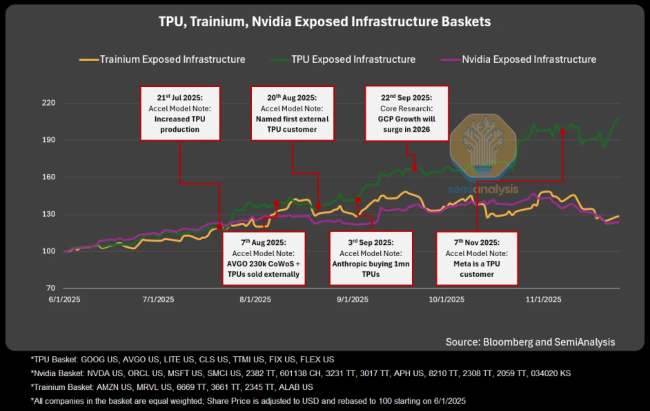
长期以来,谷歌的TPU像其搜索算法一样,是深藏不露的内部核武器。但这一策略已发生根本性逆转。最直接的案例来自Anthropic。作为能在前沿模型上媲美OpenAI的大模型公司,Anthropic已确认将部署超过100万颗TPU。这笔交易揭示了谷歌“混合销售”的新模式:首批约40万颗最新的TPUv7由博通直接出售给Anthropic,价值约100亿美元;剩余60万颗通过谷歌云租赁,涉及高达420亿美元的剩余履约义务。

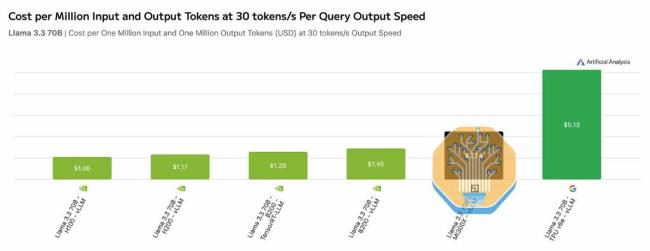
面对这一攻势,英伟达展现出防御姿态,财务团队不得不针对“循环经济”的质疑发布长文辩解。客户倒戈的理由很纯粹:在AI军备竞赛中,性能是入场券,但总拥有成本(TCO)决定生死。SemiAnalysis数据显示,谷歌TPUv7在成本效率上对英伟达构成碾压优势。从谷歌内部视角看,TPUv7服务器的TCO比英伟达GB200服务器低约44%。即便加上谷歌和博通的利润,Anthropic通过GCP使用TPU的TCO仍比购买GB200低约30%。

这种成本优势源于谷歌独特的金融工程创新——“超级云厂商兜底”。谷歌承诺,如果中间商无法支付租金,谷歌将介入兜底。这一金融工具打通了加密货币矿工与AI算力需求之间的堵点,构建了一个独立于英伟达体系之外的低成本基础设施生态。
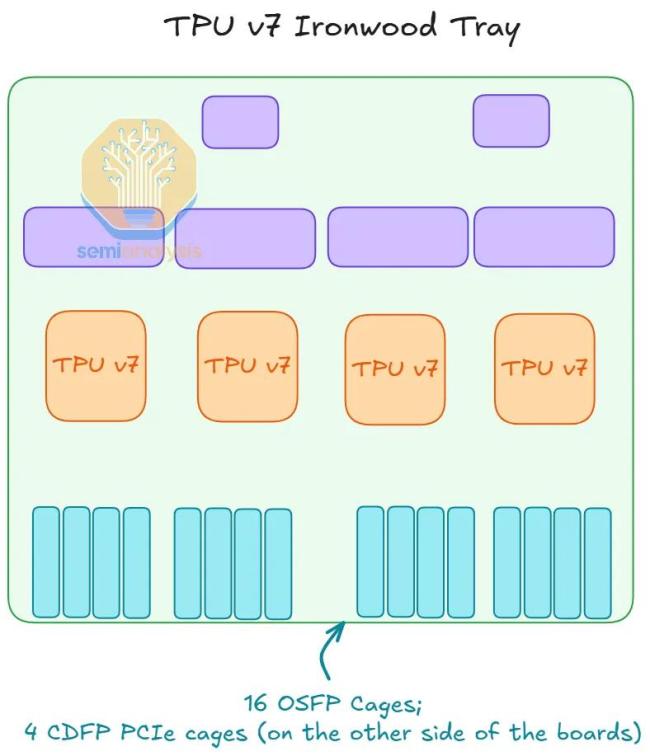
如果说价格战是战术层面的对垒,那么系统工程则是谷歌战略层面的护城河。虽然单颗TPUv7在理论峰值算力上略逊于英伟达的Blackwell,但谷歌通过极致的系统设计抹平了差距。更重要的是,它采用了更务实的设计哲学——不追求不可持续的峰值频率,而是通过更高的模型算力利用率提升实际产出。
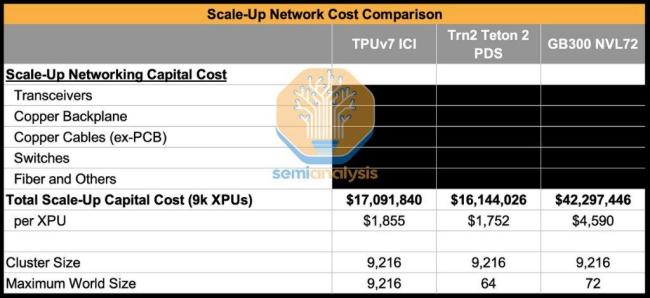
谷歌的杀手锏是其独步天下的光互连技术。不同于英伟达依赖昂贵的NVLink和InfiniBand/Ethernet交换机,谷歌利用自研的光路交换机和3D Torus拓扑结构,构建了名为ICI的片间互连网络。这一架构允许单个TPUv7集群扩展至9,216颗芯片,远超英伟达常见的64或72卡集群。这意味着如果某部分芯片故障,网络可以毫秒级绕过故障点,重新“切片”成完整的3D环面,极大地提升了集群的可用性。
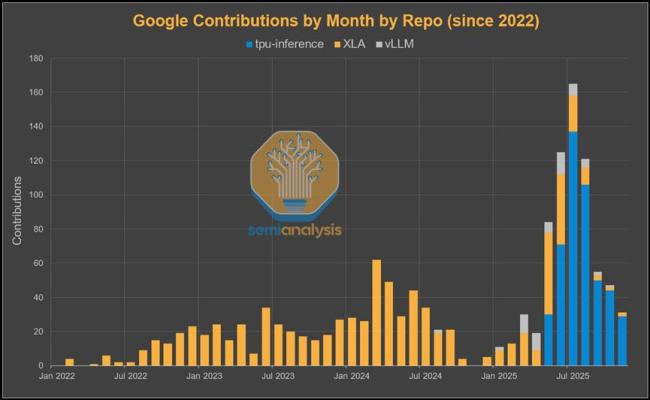
长期以来,阻碍外部客户采用TPU的最大障碍是软件。但在巨大的商业利益面前,谷歌终于放下了傲慢。SemiAnalysis报告指出,谷歌软件团队的KPI已从“服务内部”转向“拥抱开源”。此前,谷歌宣布将全力支持PyTorch Native在TPU上的运行。谷歌不再依赖低效的Lazy Tensor转换,而是通过XLA编译器直接对接PyTorch的Eager Execution模式。这使得Meta等习惯使用PyTorch的客户可以几乎无缝地将代码迁移到TPU上。

同时,谷歌开始向vLLM和SGLang等开源推理框架大量贡献代码,打通了TPU在开源推理生态中的任督二脉。这一转变意味着英伟达最坚固的“CUDA护城河”,正在被谷歌用“兼容性”填平。
这场“硅谷王座”的争夺战才刚刚开始。
 配资优秀配资门户
配资优秀配资门户
网配查提示:文章来自网络,不代表本站观点。
相关文章



热点资讯





推荐资讯
